Introduction To Micoservice Architecture
In this blog post, we will learn about microservices. We would learn why microservices are evolved and are preferred nowadays over monolithic architecture. We would also learn about a few patterns and useful ideas on microservices.
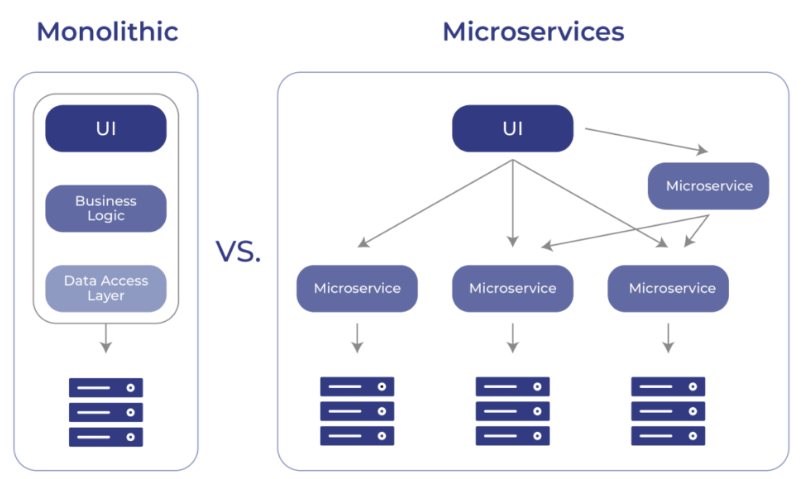
Microservice Architecture
Microservice is an architectural approach to software development, where the overall software is broken down into multiple independent and loosely coupled services, communicating over a well-defined interface. Microservices are typically structured around business needs and are owned by a small team.
Comparision with Monolith:
Earlier software development used to follow the monolith architecture, where all the processes are run as a single service. The codebase is generally used to be maintained as a single repo, and the application is used to deploy as a whole. However, there are a couple of disadvantages, which led to the large adoption of microservice:
- Scalability: As the whole application is deployed in a single go, scaling the application horizontally means a certain portion of the application goes unused, thus wasting resources
- Coupling: Monolith architecture by nature becomes highly coupled. Even though there’s a distinction between the responsibility of different modules or processes, however over a long time, these process becomes highly dependent on each other, thus causing tight coupling.
The goal of microservice architecture is to make each team:
- Autonomous: Implementation and operational decisions are independently taken
- Specialized: Focused on solving one problem well
- Built for business: Organized around business needs
Monolith to microservices:
One starting point to convert a codebase from monolithic to microservice-based is to consider cohesivity. Club the functionalities that do related work and create a microservice out of that. Start small, with a few modules, and continue to separate them. Eventually, it will result in architecture like the following:
Challenges in Adopting & Implementing Microservices:
-
Managing: As the number of microservices is increased, the complexity of managing also increases significantly, so introducing new microservice should be well planned
- Monitoring & Logging:
- Each component of all the services should be monitored
- Debugging a root cause spanning across all the services, should be easy
- Distributed tracing becomes supercritical: Eg:-Zipkin
- Blindspot can be catastrophic
- Service Discover:
With hundreds of microservices spanning thousands of servers, how can we find whom to talk to to get it done? Service discovery can be used in this case:
- i. Central Service Registry
- ii. Load-Balancer based discovery
- iii. Service Mesh
All the above-mentioned approaches have their advantages and disadvantages. We would explore them as part of a separate blog post.
-
Authentication & Authorization: Secrets can’t be made openly accessible, not even the ones used for inter-service communication. Authentication and authorization need to be set up for inter-service communication. A central internal service that issues JWT tokens is generally used.
-
Configuration Management: Each service has its own set of secrets and configs. There needs to be a way to store and access configurations centrally. Every service has its way for this is a waste of time, and should be standardized.
-
Fault-tolerance: There are many ways for the service to fail. Outages are inevitable, however, the important part is to ensure the outage isn’t bringing down the whole service itself. The microservices are supposed to be modeled around the loose coupling and asynchronous dependency.
- Internal & External testing:
- hard to test in a completely isolated environment
- hard to simulate the distributed failures
- Dependency management is a nightmare:
- i. Service dependency: Synchronous dependency may trigger cascading failures
- ii. Library/Module dependency: Without proper versioning or backward compatibility, rolling out changes becomes painfully slow
- iii. Data dependency: Services relying on data coming from other services hampers user-experience
Standardizing Microservices:
There should be a standard way to create a “good” microservice. Three verticles to standardize:
i. Monitoring: How to trace the cross-service view of a request passing through different components of a system. This is also known as distributed tracing. There is a couple of industry-provided offerings like Zipkin and AWS X-Ray tracing. As part of this, need to keep track of the following:
- how every server is doing? => CPU, memory, disk consumption
- how every service is doing? => health check
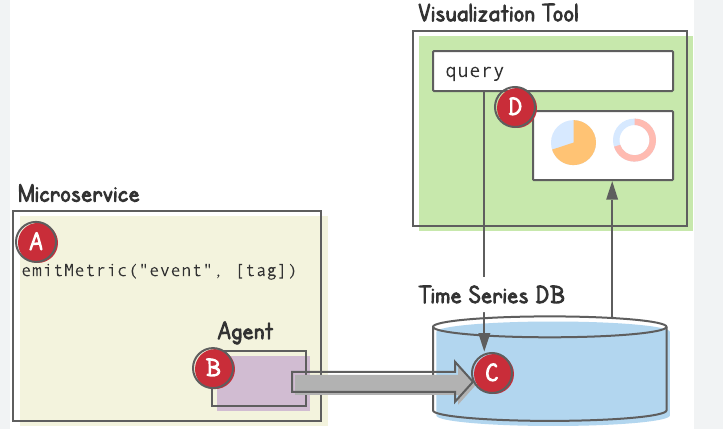
Data Collection:
- Collect metrics: CPU, RAM, Disk, N/w
- Collect logs: Application, Process, User log, SSH, OS
- Collect app metrics: 2xx, 3xx, 4xx, response time, number of requests, # of servers
- Possible tech: Prometheus, Graphine, NewReplic, Datadog
ii. Interfaces:
- How would two service talk to each other? => HTTP/REST/gRPC
- How would the end user talk to a service?
Also within a protocol, need to standardize:
- how to define routes?
- how to name the endpoints?
- how to paginate documents?
APIs:
- how to version the APIs?
- connection timeout: neither too small nor too large
- retry strategy: Exponential backoff
- payload type: JSON/XML/TXT
iii. Tolerance: What if one service bombards the other? One bad service can take down the entire infrastructure. Hence each service should shield itself. Strategies to achieve this:
- Ration the number of requests from each service
- Limit the number of outgoing calls from a service
- Have the ability to cutoff incoming resources from a service
- Have an ability to cutoff outgoing resources to a service
Profiling is one of the renowned techniques used for this.
Preparing for Integration: Do’s and Dont’s:
- Forward & Backward compatibility: Make changes such that other services don’t need to change at all. Key places to keep a close eye on:
- DB Migrations
- API Namespaces
- Message from asynchronous communications
-
Never change the type of column or attributes: Instead prefer creating a new column with a new type, which would avoid forced changes
- Dead simple consumption: Microservices are built to interact with other microservice, It should be way simple for other services to talk to your service, otherwise it wouldn’t matter how optimized the service is if it’s having a poor interface:
- Simple API
- Simple data format
- Common Protocols
-
Make API technology agnostic, and simple
- Hide Internal Implementation details: All communication should happen over public APIs. This would allow us to upgrade internal implementation logic.